
Inserting information into a computer from handwritten documents - such as inventory lists, sales slips and scientific laboratory data - has always been one of the slowest steps in automatic information processing. The usual method has been to convert the handwritten data into computer “language” by typing it on a coding machine or punching it on cards. Eventually, machines that can interpret handwriting directly will shorten the time it takes to process information, and will help man take fuller advantage of the electronic speed of computing systems.
~ Excerpt from “The IBM Pavilion” booklet, available at the 1964 World’s fair in New York.
A classic example of a problem that has traditionally been easy for humans, but difficult for computers, is handwritten digit recognition. Because of the many variations in human handwriting, early attempts to “read” handwritten digits into a computer were very limited.
It therefore seemed almost “magical” when, at the 1964 World’s Fair in New York, IBM unveiled an amazing computer system that read handwritten dates off a small card. Visitors to the “This Date in History” exhibit would write down a date on a card and feed it into the machine.

Then, the computer would convert the handwritten date into digital form, look up the date in a database of New York Times headlines, and show a headline from that day on an overhead display. Watch the first minute of this video to see a demonstration!
The results were also printed on a card that you could keep as a souvenir.


How was this achieved? Was this an early example of a machine learning-based handwritten character recognition system?
The back of the keepsake card explained to visitors how the character recognition system works:
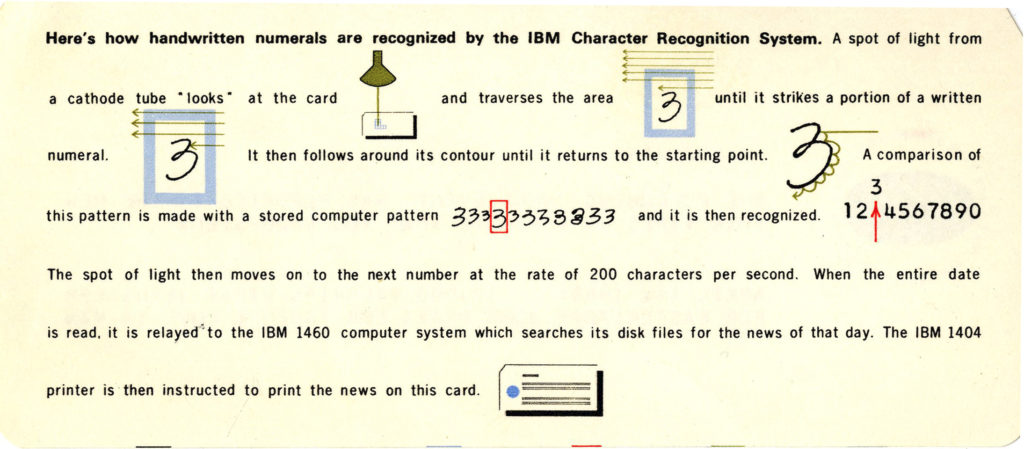
While this description has some detail about how the computer acquires the “shape” of the handwritten digit from the card using a cathode ray tube scanner (which generates voltages in proportion to the level of light reflected off the card), it’s not very clear how the computer then “recognizes” the shape.
To learn more, we will refer to the work of E. C. Greanias, a researcher at IBM Thomas J. Watson Research Center in New York who specialized in handwritten character recognition, whose work was likely the foundation for this exhibit. In a January 1963 article in the IBM Journal of Research and Development titled “The Recognition of Handwritten Numerals by Contour Analysis” there is a more detailed explanation. Open that paper, and follow along as we dig deeper!
First, there is some discussion of the challenges associated with character recognition, and the desired specifications of a character recognition system:

Greanias et al want the system to recognize handwritten digits located anywhere within a larger area, and of various sizes. This seems to rule out a naive pixel-based approach involving pre-defined rules that say (for example): “A 1 should always have writing in the horizontal center of the writing area, and should have no writing on the left and right sides of the writing area,” since this would fail to recognize a 1 written on the side of the writing area instead of the center. Greanias et al also wanted the system to tolerate variation in digit shape, minor rotation, or slant.
The next section of the paper describes in more detail how the image is acquired using the cathode ray tube scanner. This section clarifies that in a first pass over the image, the scanner acquires the size and position of the handwritten character, and then in the second pass it would acquire a more detailed contour of the handwritten character that is normalized to its position within the writing area and its size.
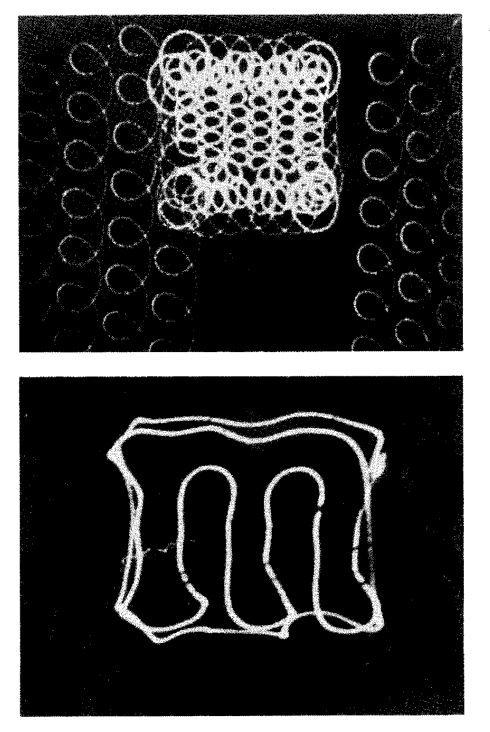
The next section of the paper gets into some detail regarding the electronic circuits used to process the scanner output. We are mainly concerned with the logic, rather than the electronics, so all we need to know is that the area with the handwritten character is divided into 12 “zones” in a 3x4 array, and the circuit determines the direction of the line within each zone (N, NE, E, SE, S, SW, W, or NW).
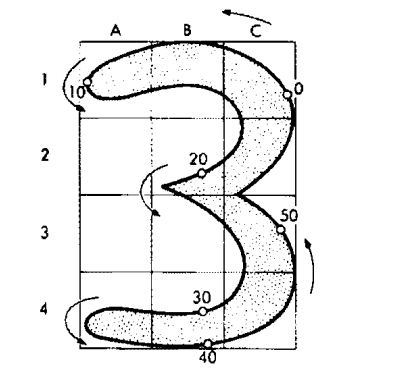
Next, we turn to the character recognition part of the system. Greanias et al explain that they had 3000 examples of handwritten digits, and used their subjective judgment to describe features that could be used to identify each type of digit - strokes (straight lines), line ends, lakes (round interior areas such as in 0, 6, or 9), bays (concave areas), etc. in one or more of the 12 “zones”.

Finally, the paper gives a detailed example with reference to a handwritten example of a 5, and shows how an electronic circuit identifies what features are present in an image as the scanner moves along the countours of the handwriting. In this example, as the scanner moves along the edge of the written digit,
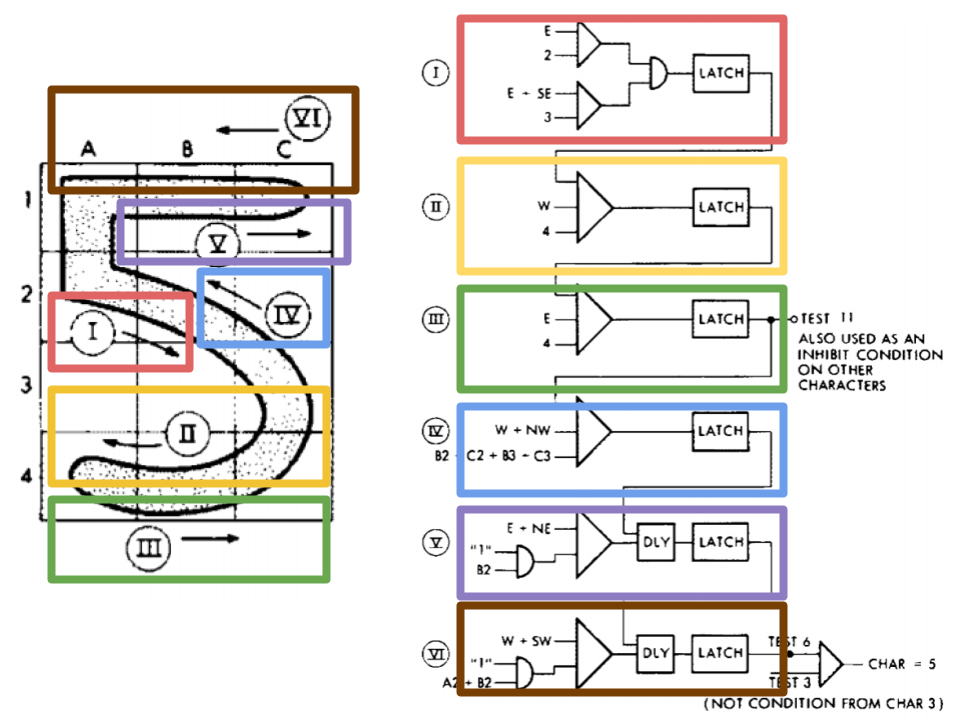
If this sounds complicated and fragile… it definitely was! For 1964, though, it was impressive. In a press release, IBM brags that the system is extremely flexible, with only minor constraints on the types of handwriting it can read:
The only constraints imposed by the scanner are that writers must avoid large embellishments such as curlicues and “tails,” excessive slanting, large breaks in the lines that compose the number, writing too small or too large beyond a 4-to-1 range in height and running numerals together.
~ Excerpt from an IBM Press Release
In an experimental evaluation on new samples (see Crook and Kellogg in the reference list), 92% of digits were recognized correctly. However, the subjects could be “trained” to write digits that were more easily recognizable by the machine, bringing the accuracy up to 99.3% for digits written by “trained” writers. This was considered exceptionally good.
